Im Jahr 1982 hat Shamir einen Algorithmus veröffentlicht, der das Ende des Merkle-Hellman Kryptosystems bedeutete [SH82]. Der Algorithmus versucht, aus einem gegebenen öffentlichen Schlüssel B ein Paar (U, M) zu ermitteln. Mit dem Paar (U, M) und B kann eine superansteigende Folge A konstruiert und somit jede Nachricht entschlüsselt werden, die zuvor mit B chiffriert wurde. Das Paar (U, M) ist ein Trapdoor-Paar.
Erinnerung:
Ein Merkle-Hellman Schlüsselpaar wird erzeugt, indem eine superansteigende
Folge A = (a1, ..., an), ein Modulus
M mit M > a1 + ... + an sowie eine weitere Zahl W
< M mit ggT(M, W) = 1 gewählt werden. Da W relativ prim zu M ist, existiert eine Zahl
U < M mit UW = 1 (mod M). Das Tupel (A, M, W) bildet den privaten Schlüssel.
Der öffentliche Schlüssel wird durch die Vorschrift bi = aiW mod M ermittelt.
Umgekehrt lassen sich die Komponenten von A durch ai = biW-1 mod M = biU mod M errechnen, sofern M und W bekannt sind.
Gegeben seien nun drei private Schlüssel kpriv1, kpriv2
und kpriv3 mit
| Schlüssel |
|
|
|
U = W-1 (mod M) |
| kpriv1 | 2, 4, 8 | 23 | 3 | 8 (8*3 = 1 mod 23) |
| kpriv2 | 1, 2, 6 | 35 | 6 | 6 (6*6 = 1 mod 35) |
| kpriv3 | 2, 4, 7 | 40 | 23 | 7 (7*23 = 1 mod 40) |
Gemäß der Formel bi = aiW mod M lauten
die entsprechenden öffentlichen Schlüssel:
| Schlüssel | b1 = a1W mod M | b2 = a2W mod M | b3 = a3W mod M |
| kpub1 | 6 = 2*3 mod 23 | 12 = 4*3 mod 23 | 1 = 8*3 mod |
| kpub2 | 6 = 1*6 mod 35 | 12 = 2*6 mod 35 | 1 = 6*6 mod 35 |
| kpub3 | 6 = 2*23 mod 40 | 12 = 4*23 mod 40 | 1 = 7*23 mod 40 |
Die öffentlichen Schlüssel sind identisch, obwohl drei verschiedene private Schlüssel zur Konstruktion genommen wurden. Für einen öffentlichen Knapsack-Schlüssel B gibt es also nicht nur einen privaten Schlüssel. Wie sich später herausstellen wird, gibt es sogar unendlich viele private Schlüssel.
Jedes Paar (U, M) kann zur Bildung der Menge A herangezogen werden, vorausgesetzt
Der Algorithmus von Shamir zielt darauf ab, aus dem öffentlichen Knapsack-Schlüssel B ein Trapdoor-Paar (U, M) zu ermitteln, so dass die Folge {ai = biU mod M}i=1...n superansteigend ist. Der Algorithmus läuft in zwei Schritten ab:
Für eine genauere Analyse wird von folgenden Werten ausgegangen:
Mit den Parametern n = 100 und d = 2 wächst A von 100 bit für a1 bis zu 199 bit für a100.
Der Modulus M0 ist eine 200 bit Zahl und die einzelnen bi
haben die Größenordung von 200 bit.
Gegeben sei nun ein öffentlicher Knapsack-Schlüssel B = (b1, ..., bn). Der unbekannte Modulus sei M0 und W0 der unbekannte Multiplikand. Weiterhin sei U0 = W0-1 das Inverse Element zu W0 (mod M0).
Gleichzeitig wird der Wertebereich von U erweitert, so dass U reelle Werte annehmen kann. Da U kleiner als M0 ist, kann U0 Werte aus dem Intervall [0, M0[ annehmen. Wird in die Funktion fi für U der Wert U0 eingesetzt, erhält man gerade die i-te Komponente von A:
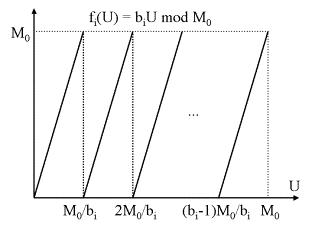
Der Graph der Funktion fi hat dabei folgendes Aussehen:
Analyse der ersten Funktion f1(U) = b1U mod M0:
Da M0 größer ist als die Summe aller ai,
gilt insbesondere, dass M0 viel größer ist als a1.
Die Komponente a1 ist nach Konstruktion eine dn-n bit Zahl.
Der (unbekannte) Modulus M0 ist eine dn bit Zahl. Da b1
etwa die Größenordung von M0 hat, ist auch b1
eine dn bit Zahl.
Der unbekannte Wert U0 macht gemäß der Formel
a1 = b1U0 mod M0 aus einer
dn bit Zahl eine dn-n bit Zahl. Diese Eigenschaft von U0 schränkt
den Bereich ein, in dem U0 liegen kann.
Die folgende Abbildung versucht zu verdeutlichen, dass U0
sehr nahe an einer Nullstelle der f1-Kurve liegen muss. Der
Abstand zur nächsten links von U0 liegenden Nullstelle
beträgt nicht mehr als 2-n.
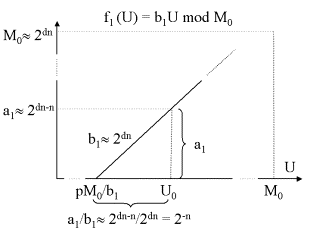
Eine Analyse der zweiten Funktion, f2(U) = b2U mod M0 ergibt ein ähnliches Ergebnis. Da a2 eine dn-n+1 bit Zahl und b2 eine dn bit Zahl ist, beträgt der Abstand von U0 zur nächsten links von U0 liegenden Nullstelle nicht mehr als 2-n+1. Auch hier liegt U0 sehr nahe an einem Minimum.
Da U0 sehr nahe an einem Minimum der f1- und f2-Kurve liegt, folgt, dass diese beiden Nullstellen sehr nahe beieinander liegen. Dabei liegt die Nullstelle der zweiten Kurve höchstens 2-n+1 links der Nullstelle der f1-Kurve und höchstens 2-n rechts von ihr.
Eine Analyse der weiteren Funktionen f3, f4, ...
ergibt die gleiche Feststellung: der unbekannte Wert U0
liegt in der Nähe einer Nullstelle dieser Funktionen. Folglich liegen
alle diese Nullstellen nahe beieinander.
Anstatt den Wert U0 zu finden, kann man sich darauf beschränken, Bereiche zu finden, in denen f1, f2, f3, ... eine Nullstelle besitzen.
Diese Bereiche werden Anhäufungspunkte (accumulation points)
genannt.
Nun stellt sich die Frage, wieviele Funktionen analysiert werden müssen,
um eine möglichst geringe Anzahl an Anhäufungspunkten zu erhalten.
Dazu sei k die Anzahl der Funktionen, die zu deren Ermittlung genommen werden.
Betrachte das p-te Minimum der f1-Kurve, gelegen an der
Stelle U = pM0/b1. Die am nahesten an pM0/b1
gelegene Nullstelle der i-ten Funktion liegt irgendwo im Intervall [pM0/b1 - M0/(2bi), pM0/b1 + M0/(2bi)], da zwei aufeinander folgende Nullstellen der i-ten Funktion im Abstand M0/bi folgen. Angenommen, die Lage der verschiedenen Minima in diesem Intervall sind Zufallsvariablen mit gleicher Wahrscheinlichkeitsverteilung. Dann kann die Wahrscheinlichkeit, dass die Nullstellen der Kurven f2, f3, ..., fk nahe genug am p-ten Minimum der f1-Kurve liegen, abgeschätzt werden durch 2-n+1×2-n+2×...×2-n+k-1, was in etwa 2-kn+n+k2/2 entspricht. Da die erste
Funktion insgesamt b1 Minima besitzt, beträgt die erwartete
Anzahl an Anhäufungspunkten b1×2-kn+n+k2/2, ungefähr 2dn-kn+n+k2/2.
Dieser Ausdruck wird kleiner als Eins, wenn (k-d-1)n > k2/2.
Für große n ist diese Bedingung erfüllt, falls k > d+1.
Für d = 2 heisst das, dass nur vier Funktionen betrachtet werden müssen,
um nicht zu viele Anhäufungspunkte zu erhalten. Dabei ist d wiederum die Proportionalitätskonstante.
Bevor mit dem Auffinden der Anhäufungspunkte fortgefahren wird,
noch eine Beobachtung über die Kurven fi:
diese Funktionen sind definiert mod M0. Dieser Wert ist
nicht bekannt. Die Positionen der Nullstellen der verschiedenen Funktionen
sind aber unabhägnig von M0. Sie hängen von der Steigung
ab. Die Steigung von fi lautet bi. Dividiert man
daher beide Koordinaten von fi durch den (unbekannten) Modulus
M0, erhält man n Funktionen fi(V) = biV
mod 1. Die Unbekannte in dieser Funktion ist nun V = U/M0. Der Definitionsbereich ist entsprechend [0, M0/M0[ = [0, 1[. Die Steigung der Funktion fi beträgt bi. Die Nullstellen liegen nun bei V = 0, 1/bi, 2/bi, ..., (bi -1)/bi; der Abstand zweier Nullstellen lautet nun 1/bi.
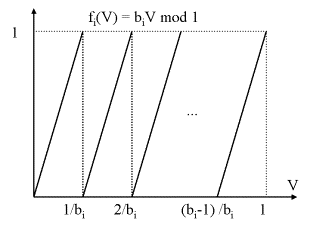
Vor Division durch M0 betrug der Abstand von U0 zur nächsten links liegenden Nullstelle der ersten Funktion nicht mehr als 2-n. Dieser Abstand ist reduziert um M0 und beträgt nun nicht mehr als 2-dn -n, da M0 eine dn bit Zahl ist.
Damit nun das p-te Minimum der f1-Kurve einen Anhäufungspunkt darstellt, müssen in seiner Umgebung Nullstellen von f2, f3 und f4 sein. Das p-te Minimum von f1 liegt bei V = p/b1. Die Bedingung, dass die q-te Nullstelle von f2 um höchstens den Wert d1 von p/b1 entfernt liegt, wird durch die Ungleichung
Das Lösen der Ungleichungen ist ein Integer Programming Problem. Solch ein Problem ist polynomiell in der Größe der Koeffizienten lösbar, wenn die Anzahl der Unbekannten fest ist.
Durch Lösen dieser Ungleichungen erhält man Werte für p, so dass
Für jeden im Schritt 1 erhaltenen Anhäufungspunkt p wird nun eine genauere Analyse durchgeführt. Dazu werden alle n Funktionen betrachtet. Zum Ermitteln der Anhäufungspunkte wurden nur vier Funktionen berücksichtigt, daher kann es vorkommen, dass ein p-Wert zwar für die ersten vier Kurven einen Anhäufungspunkt darstellt, jedoch nicht für die übrigen Funktionen.
Sei nun p ein Anhäufungspunkt, im Schritt 1 erhalten. Betrachtet wird jetzt das Intervall [p/b1, (p+1)/b1[, das Intervall zweier aufeinander folgender Nullstellen der f1-Kurve.
Für das Intervall [p/b1, (p+1)/b1[ werden
nun die Nullstellen aller Funktionen f2, f3, ...,
fn ermittelt. Diese Nullstellen werden aufsteigend nach dem v-Wert sortiert.
Sei {v1, v2, ..., vs} die Liste aller
Nullstellen in [p/b1, (p+1)/b1[. Innerhalb eines
Intervalls [vj, vj+1[ gibt es, bis auf vj
selbst, keine weiteren Nullstellen. Jede Funktion fi kann daher in diesem
Intervall als Geradengleichung ausgedrückt werden:
Die folgende Abbildung zeigt, wie sich die Funktion fi zwischen Nullstellen als Geradengleichung beschreiben lässt. Im ersten Intervall [0, 1/bi[ heisst die Gleichung fi(V) = biV. Im nächsten Intervall [1/bi, 2/bi[ wird der T-Wert erhöht, da fi in [0, 2/bi[ genau einmal modulo 1 reduziert wurde.
In [1/bi, 2/bi[ lautet die Darstellung fi(V) = biV -1. In [2/bi, 3/bi[ wurde zweimal modulo 1 reduziert: fi = biV -2. Auf diese Weise lässt sich fi in jedem Intervall zwischen zwei aufeinander folgenden Nullstellen eindeutig als Geradengleichung darstellen.
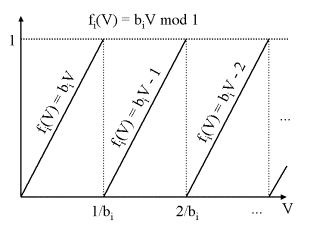
Untersucht wird nun, ob in [vj, vj+1[ ein Subintervall
existiert, so dass die Funktionen in diesem Subintervall superansteigend
sind und zudem ihre Summe < 1 ist. Wichtig ist, dass V in das Intervall
[vj, vj+1[ eingeschränkt wird, da nur in einem
solchen Intervall jede Funktion eindeutig als Geradengleichung beschrieben
werden kann.
Für n Funktionen erhält man n-1 Ungleichungen in der Unbekannten
V, um die superansteigende Eigenschaft zu erfüllen.
Die erste Ungleichung, f2(V) > f1(V) <=> b2V - T2, j > b1V - T1, j, aufgelöst nach V, ergibt zum Beispiel
Die Summe aller Funktionen ist kleiner als Eins für
Nach Auswerten aller Ungleichungen sind in [vj, vj+1[ die Bedingunen möglicherweise nicht erfüllbar und es ist ein in [vj, vj+1[ leeres Unterintervall entstanden. In diesem Fall wird das nächste Intervall [vj+1, vj+2[ untersucht. Dabei ändert sich genau ein T-Wert. Der T-Wert der Funktion, die an der Stelle vj+1 ein Minimum besitzt, wird um Eins erhöht, da die entsprechende Funktion in ]0, vj+1] nun eine Nullstelle mehr hat. Alle anderen T-Werte bleiben unverändert.
Sei nun ]ul, ur[ das nicht-leere Subintervall, welches nach Auswerten aller Bedingungen erhalten wurde. Für jedes V aus ]ul, ur[ und für alle Funktionen fi gilt:
Sei nun p/q eine rationale Zahl aus ]ul, ur[. Es gilt:
 |
DES |  |