Recall, how a Merkle-Hellman key-pair is generated:
Choose a superincreasing sequence A = (a1, ..., an), a modulus M with M > a1 + ... + an and a multiplier W with 1 <= W < M. Additionally, W must be relative prim to M, i.e. gcd(M, W) = 1. This choice of W guarantees an inverse element U, such that UW = 1 (mod M). M, W and the set A constitutes the private key, whereas the public key is the set of integers B = (b1, ..., bn), with bi = aiW mod M.
Provided, M and W are given, the components ai may be computed by ai = biW-1 mod M = biU mod M.
| key |
|
|
|
U = W-1 (mod M) |
| kpriv1 | 2, 4, 8 | 23 | 3 | 8 (8*3 = 1 mod 23) |
| kpriv2 | 1, 2, 6 | 35 | 6 | 6 (6*6 = 1 mod 35) |
| kpriv3 | 2, 4, 7 | 40 | 23 | 7 (7*23 = 1 mod 40) |
Get the corresponding public keys by computing bi = aiW mod M. The public keys are
| key | b1 = a1W mod M | b2 = a2W mod M | b3 = a3W mod M |
| kpub1 | 6 = 2*3 mod 23 | 12 = 4*3 mod 23 | 1 = 8*3 mod |
| kpub2 | 6 = 1*6 mod 35 | 12 = 2*6 mod 35 | 1 = 6*6 mod 35 |
| kpub3 | 6 = 2*23 mod 40 | 12 = 4*23 mod 40 | 1 = 7*23 mod 40 |
The keys kpub1, kpub2 and kpub3 are indentical, though three different private keys were used. Obviously, there are many private keys producing the same public key. Indeed, as will turn out later, there are infinetely many private keys corresponding to a public key.
Every pair (U, M) can be used to get the (secret) set A, provided that
The aim of the presented algorithm is to compute a trapdoor pair, such that the resulting set A = {ai = biU mod M}i=1...n is a superincreasing one. The algorithm is divided into two parts:
To make the analysis easier, the following values are used:
Setting n = 100 and d = 2, the components of A increase in size from 100 bits for a1 up to 199 bits for a100.
The modulus M then is a 200 bit number.
Given a public key B = (b1, ..., bn). Let M0 be the (unknown) modulus and W0 the (unknown) multitplier used to construct the public key B. The inverse element to W is denoted by U0.
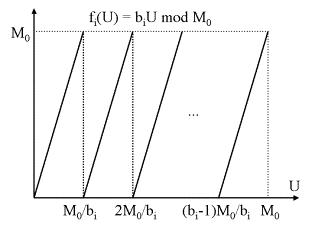
Consider arbitrary real positive values for U. As U is less than M0, the functions are defined in [0, M0[. For U = U0, function i produces exactly ai:
The graph of function i is as follows:
Now analyze f1(U) = b1U mod M0:
The modulus M0 is greater than the sum of all ai. So M0 is much bigger than a1.
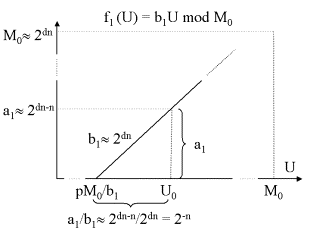
The integer a1 is a dn-n bit number, M0 a dn bit number as is b1. So the unknown U0 transforms a dn bit number to a dn-n bit number.
The following image tries to make clear, that the unknown U0 must be located near a minima of the first function. The distance to the next left minima is less than 2-n.
Doing the same analysis with funcion f2, the result is the same. The unknown U0 is again near a minima of the second function. As a2 is a dn-n+1 bit number, U0 transforms a dn bit number to a dn-n+1 bit number. For that reason, U0 is located at most 2-n+1 right of a minimum of function two.
Since U0 is located near a minimum of f1 as well as f2, there are minima of f1 and f2 being very close to another. The minimum of f2 is at most 2-n+1 to the left and at most 2-n to the right of the minimum of f1.
The same analysis holds for f3, f4, ...
U0 is located near a minimum of all these functions, so the minima are very close to each other. The problem of finding U0 itself can be reformulated as the problem of finding accumulation points of minima of the various functions.
Let k be the number of functions, used to get the accumulation points. Consider the p-th minimum of f1, located at U = pM0/b1. The nearest minimum of fi to pM0/b1 is in the interval [pM0/b1 - M0/(2bi)], because the distance of two successive minima of fi is M0/bi. Assume now, that the minima in [pM0/b1 - M0/(2bi)] are random variables with uniform probability distributions. Then the probability, that the mimima of f2, ..., fk are sufficiently close the p-th minimum of function one, can be estimated by 2-n+1×2-n+2×...×2-n+k+1, which is about 2-kn+n+k2/2. As there are b1 different minima of f1, the expected number of accumulation points is b1×2-n+1×2-n+2×...×2-n+k+1, which is about 2dn-kn+n+k2/2. This expression is less than 1, if (k-d-1)n > k2/2. If n is large, this expression is true, if k > d+1. Using d=2, only 4 functions have to be analyzed for getting accumulation points in number not too much. Here, d is again the proportionality constant.
But prior to computing the accumulation points, one problem remains: the functions are defined modulo M0. This number is unknown. The minima of the i-th function depend on the slope, which is bi. By dividing both coordinates of the i-th function by M0, new functions fi are definded as follows: fi(V) = biV mod 1, with the new variable V in [0, 1[. The slope still is bi and the number of minima remains bi. The locations of the minima are now at V = 0, 1/bi, 2/bi, ..., (bi-1)/bi and the distance of two minima is reduced to 2-dn-n, because M0 is a dn bit number.
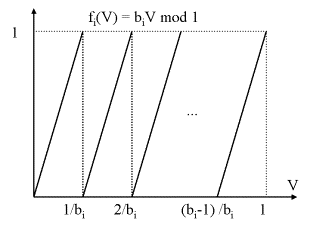
The unknown value V0 now is at most 2-dn-n right to a minimum of function f1.
To get the accumulation points, consider the p-th minimum of f1, located at p/b1. To be an accumulation point, there have to be minima of f2, f3 and f4 near p/b1. The q-th minimum of f2 is at V = q/b2, the r-th minimum of f3 at V = r/b3 and the s-th minimum of f4 is at V = s/b4. So all these minima must be close to p/b1. Expressed as a formula, this means that
By mulitplying with the denominators, the follwing equivalent system of inequalities is obtained:
This is an integer programmming problem. Lenstra has showed, that this can be solved in polynomial time in the size of the coefficients, if the number of variables is fixed.
With solving this system of inequalites, numbers p are computed for which
With the end of step one, all accumulation points, satisfying the inequalities are found. For each of these accumulation points, perform a finer analysis. Consider now all n functions. To obtain the accumulation points, only four functions were used. For that reason, you might get points, f2, f3 and f4 have a close minimum to it, but not all the other functions.
Now let p be an accumulation point. Consider the interval [p/b1, (p+1)/b1[, which is the interval of two successive minima of function f1.
For this interval, get all the minima of all functions and sort them in increasing order by the v-coordinate.
Let {v1, v2, ..., vs} be the list of all minima in [p/b1, (p+1)/b1[. The only minimum in [vj, vj+1[ is located at vj, so every function fi may be described as a linear segment:
The following image explains the fact, that within two minima, function i may be written as a linear segment. Within ]0, 1/bi[, no minima exist. In the next interval, fi is exactly once reduced modulo 1, so the T-value is increased and is now 1. The line segment in [1/bi, 2/bi[ may be written as fi = biV - 1, V in [1/bi, 2/bi[. Turning to [2/bi, 3/bi[, the segment is now fi = biV mod 2, because a further minimum exists at V = 2/bi. So between two neighbouring minima, fi may be written as a line segment.
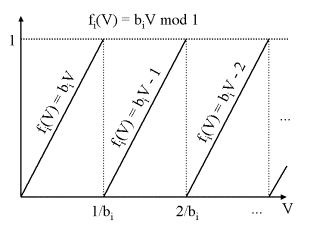
The task is now to scan every interval [vj, vj+1[, if there exists a subinterval satisfying the supericreasing property and in which the sum of all functions is less than one. It is important to limit the value V into [vj, vj+1[. Only in such an interval, all functions can be written in the form fi = biV - Ti, j.
Because there are n functions, there are n-1 inequalities. All of these inequalities have to be evaluated to satisfy the superincreasing property.
For example, to satisfy the condition that f2 is greater than f1, V is limited by
As stated above, if one inequality is not satisfiable in [vj, vj+1[, turn to the next interval [vj+1, vj+2[ and try again. Exactly one T-value changes, namely the T-value of that function having a minima at vj+1. This value is increased by one. All other values remain unchanged.
Now suppose, the resulting interval is nonempty. Let ]ul, ur[ be that interval. For every V in ]ul, ur[, all functions fi satisfy
Let p/q be an arbitrary rational number in ]ul, ur[. The following holsd true
 |
DES |  |