Wörterbuch-Techniken
Die Idee für Wörterbuch-Techniken ist folgende: Konstruiere eine Liste der Muster, die im Text vorkommen, und codiere die Muster als Indizes der Liste. Diese Methode ist besonders nützlich, wenn sich eine kleine Anzahl Muster sehr häufig im Text wiederholt. Dann gibt es zwei Möglichkeiten:
Wenn wir genügend Kenntnisse über den Text haben, dann benutzen wir das statische Verfahren, sonst die dynamische Methode.
1 Statisches Verfahren
Die meisten statischen Verfahren sind nur für ganz besondere Fälle nützlich. Zum Beispiel für die Kompression der Files, in denen die Leistungen von Studenten gespeichert sind. Dort kommen Wörter wie "Name", "Matrikelnummer" und "Note" sehr oft vor. Hier beschreiben wir aber eine Methode, die etwas allgemeiner angewandt werden kann, nämlich den Digramm-Codier-Algorithmus. Für dieses Verfahren enthält das Wörterbuch alle einzelnen Buchstaben und dann möglichst viele Paare von Buchstaben, die wir Digramme nennen. Z.B. für ein Wörterbuch der Länge 256 sind die ersten 95 Einträge die druckbaren ASCII-Zeichen und die restlichen 161 Einträge sind diejenigen Paare der Symbole, die am häufigsten benutzt worden sind. Dann codiert man jedes Symbol bzw. jedes Symbol-Paar mit 8 Bits.
2 Dynamisches Wörterbuch
Alle wichtigen Verfahren dieser Familie basieren auf zwei Algorithmen, die von Jacob Ziv und Abraham Lempel 1977 bzw. 1978 beschrieben wurden, nämlich LZ77 und LZ78. Hier beschreiben wir die grundlegenden Algorithmen und ihre Varianten:
LZSS { Lempel-Ziv-Storer-Szymanski (gzip, ZIP und andere),
LZW { Lempel-Ziv-Welch,
LZC { Lempel-Ziv Compress und
LZMW (Unix Compress, GIF).
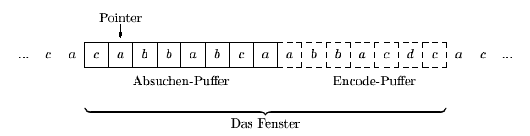
LZ77 (auch sliding windows Algorithmus genannt) bearbeitet den Text durch ein Fenster, das durch denText verschoben wird. Das Fenster hat zwei Teile: den Absuch-Puffer und den Codier-Puffer. Der erste Puffer enthält das Fragment des Textes, der bis zu einem bestimmten Zeitpunkt verarbeitet wurde und die Zeichenfolge im Puffer dient als Wörterbuch, um die Zeichen im Codier-Puffer zu codieren. Als Beispiel siehe Abbildung unten, in der die Länge des Puffers 8 bzw. 7 ist.
Um einen neuen Code zu konstruieren, benutzt LZ77 das folgende Verfahren:
Verschiebe den Pointer auf das erste Symbol von rechts im Absuch-Puffer. Dann sei Startsymbol, S := "das erste Symbol (von links) im Codier-Puffer" und offset, L := 0.
Verschiebe den Pointer im Absuch-Puffer so weit nach links bis er das Zeichen findet, das gleich dem Startsymbol ist, oder die linke Grenze des Puffers erreicht hat. Wenn die Grenze des Puffers erreicht ist, dann gib als Code (offset, L, K(S)) aus, wobei K(S) der Code des Zeichens S ist; sonst geh zum nächsten Schritt.
Lies Zeichen für Zeichen gleichzeitig vom Startsymbol und Pointer so lange, bis die Zeichen gleich sind. Wenn die Länge der durchgelesenen Zeichenfolgen größer als L ist, dann nimm diese Länge als neuen Wert für L und den Abstand des Pointers zur rechten Grenze des Absuch-Puffers als neuen Wert für offset. Weiterhin nimm das L+1-ste Symbol des Codier-Puffers als S und beginne so wieder mit Schritt 2.
Wenn der Code fertig ist, dann verschiebt man das ganze Fenster um L+1 Symbole, um einen neuen Code zu konstruieren. Als Beispiel betrachten wir, wie der Algorithmus den Text: abaabbabaacaacabb codiert. Das Zeichen eof steht für das Ende des Textes.

Beobachten Sie eine interessante Sache, die in Zeile 6 vorkommt: Die Zeichenfolge der Länge 4, die mit offset = 3 im Absuch-Puffer anfängt, endet im Codier-Puffer. Natürlich ist eine solche Situation sehr günstig, denn, je länger die Zeichenfolgen, desto kürzer der gesamte Code. Das Problem ist aber: Können wir solche 'überlappende' Zeichenfolgen eindeutig decodieren?
Wir zeigen unten, daß das Decodierungsverfahren für LZ77 auch in solchen Fällen korrekt funktioniert.
Das Decodierungsverfahren läuft ganz natürlich. Anstelle einer formalen Beschreibung zeigen wir zwei Beispiele, in denen die Länge der Absuch-Puffer 7 ist. Nehmen wir an, daß der Inhalt des Absuch-Puffers sowie der nächste Code die Eingaben des Verfahrens sind.
Beispiel: Der Inhalt des Absuch-Puffer ist: aabbacda und der Code: (7; 4;K(a)).
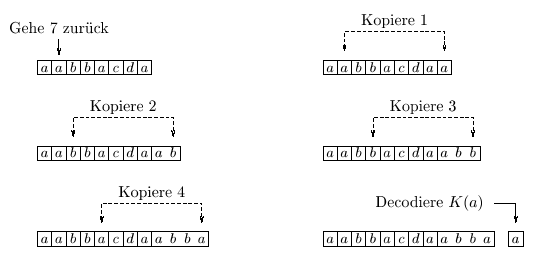
Beispiel Der Inhalt des Absuch-Puffer ist: abcabca und der Code: (3; 5;K(d)) (die Decodierung für eine 'überlappende' Zeichenfolge).

LZSS ist eine Variante von LZ77, die im Ausgabecode keinen Code für das nächste Zeichen angibt. Jetzt hat jeder Ausgabecode eins von zwei Formaten:
(0; offset, Länge),
(1; Zeichen).
Typischerweise konstruiert LZSS den Code des ersten Formats, wenn die Länge größer als 2 ist, und dann benutzt der Algorithmus die Huffman- Codierung, um die Reihenfolge von 'Ausgabecode-Symbolen' zu codieren. In der Praxis ist die Länge des Fensters gleich 32:
Beispiele:
Eingabe: a a a a a a
Ausgabecode: (1; a) (0; 1; 6) (1; eof)
Eingabe: a a a b a b a b a
Ausgabecode: (1; a) (1; a) (1; a) (1; b) (0; 2; 5) (1; eof)
LZ77 (und seine Variante) bearbeitet besonders schlecht Eingaben, in denen sich Zeichenfolgen be nden, die sich im Eingabetext in größerem Abstand wiederholen, als die Länge des Fensters erfassen kann. Zum Beispiel im Text:
![]()
Der Algorithmus kann die Zeichenfolgen, die sich im Text oft wiederholen, nicht komprimieren (wegen der Länge des Fensters) und er konstruiert für diesen Fall eine sehr uneffiziente Ausgabe. Die nächste Algorithmen werden die Texte mit solchen Eigenschaften viel besser bearbeiten. Wir betrachten zuerst das grundlegende LZ78 Komprimierverfahren. Dieser Algorithmus speichert die Informationen über die Zeichenfolgen, die er im Eingabetext findet, in der Matrize Wöterbuch. Am Anfang ist diese Matrize leer, und dann speichert der Algorithmus im Wörterbuch sukzessiv neue Zeichenfolgen und gleichzeitig generiert er die Ausgabecodes für diese Folgen. Jeder Code hat das Format: (i; k), wobei i der Index zum Wörterbuch ist und k der Code eines einzelnen Zeichens. Das heißt, daß jedes Paar (i; k) eine Zeichenfolge codiert, die eine Verkettung zweier Wörter ist: das erste Wort mit der Länge > 0 und das zweite mit der Länge 1. Um den neuen Code zu generieren, findet der LZ78-Algorithmus im Eingabetext die längste Zeichenfolge w, die schon im Wörterbuch gespeichert wurde, und nimmt als i den Index für w. Wenn das Wort w leer ist, dann nehmen wir i = 0 an. Dann liest der Algorithmus das nächste Zeichen Z, fügt wZ dem Wörterbuch hinzu und gibt (i;K(Z)) aus. Für K(Z) nehmen wir den Code für das Zeichen Z an so lange, bis der Algorithmus das erste Mal die Zeichenfolge wZ betrachtet, wobei w ein Leerwort ist. Dann ist K(Z) gleich dem Index der Matrize Wörterbuch für dieses Zeichen. Das folgende Beispiel zeigt, wie der LZ78-Algorithmus mit der Eingabe abababcabac funktioniert.
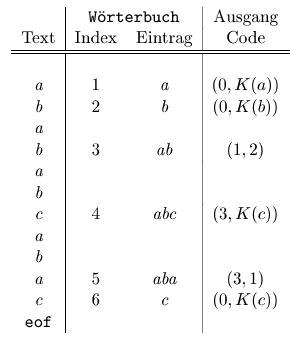
Der Dekomprimieralgorithmus für die LZ78-Methode läuft ganz einfach: Er startet mit der leeren Matrize Wörterbuch und dann rekonstruiert er sie.
Das LZW Komprimierverfahren, das Terry Welch 1984 entwickelt hat, ist eine Variante von LZ78. LZW gibt im Ausgabecode keinen Code für die Zeichen an, und als Codewörter benutzt der Algorithmus direkt die Indizes des Wörterbuches. Das Verfahren startet mit dem Wörterbuch, das die einzelnen Standardzeichen enthält. Nehmen wir an, daß wir 256 solche Zeichen betrachten werden und daß die Indizes der Matrize Wörterbuch mit 0 anfangen. Der Codier-Algorithmus sieht folgendermaßen aus:

Eine wichtige Eigenschaft ist, daß der Codier-Algorithmus einen Code für ein Wort wZ genau dann ausgibt, wenn er früher mindestens einmal das Wort im Text getroffen hat. Diese Eigenschaft spielt eine entscheidende Rolle bei der Decodierung.
Das folgende Beispiel zeigt, wie der Algorithmus mit der Eingabe abababcabac funktioniert (vergleichen Sie LZW mit LZ78 bei gleicher Eingabe, das haben wir früher betrachten).
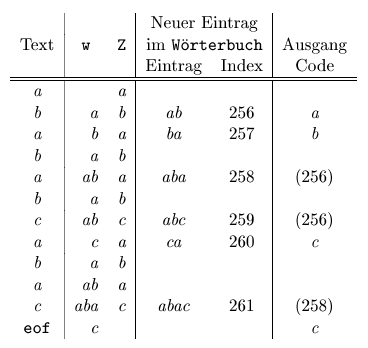
Das zweite Beispiel zeigt, wie der LZW einen Text mit vielen überlappenden Zeichenfolgen codiert.

Um den Code zu dekomprimieren, startet der Algorithmus mit der Matrize Wörterbuch, die die einzelnen Standardzeichen enthält (wie beim Codier-Verfahren) und dann rekonstruiert er die Matrize. Der Decodier-Algorithmus sieht folgendermaßen aus:

Das Applet soll veranschaulichen, wie die obengenannten Algorithmen ablaufen.
Gezeigt werden 2 Verfahren LZW und LZ77.
Handhabung des Applets:
Das Applet wurde entwickelt und realisiert von Alexander Grünhage im Rahmen der Datenkommpressionsvorlesung der Universität Tübingen.